If there is one thing we’ve learned from vulnerabilities like Log4Shell, Heartbleed, Apache Struts, Shellshock, and many others, it’s that for the components that power the web—the fabric of the internet—most organizations are underprepared. Security isn’t absolute; it’s a continuously evolving domain and we must plan accordingly.
That means governance and defense-in-depth fundamentals are critical. In this article we focus on one piece of your program—incident response—and use Log4Shell as a guiding example.
A Basic Cybersecurity Framework
Before diving into the example, let’s align on framework fundamentals. We’ll leverage the U.S. National Institute of Standards and Technology (NIST) Cybersecurity Framework to illustrate why “Respond” must be a core function of your program.
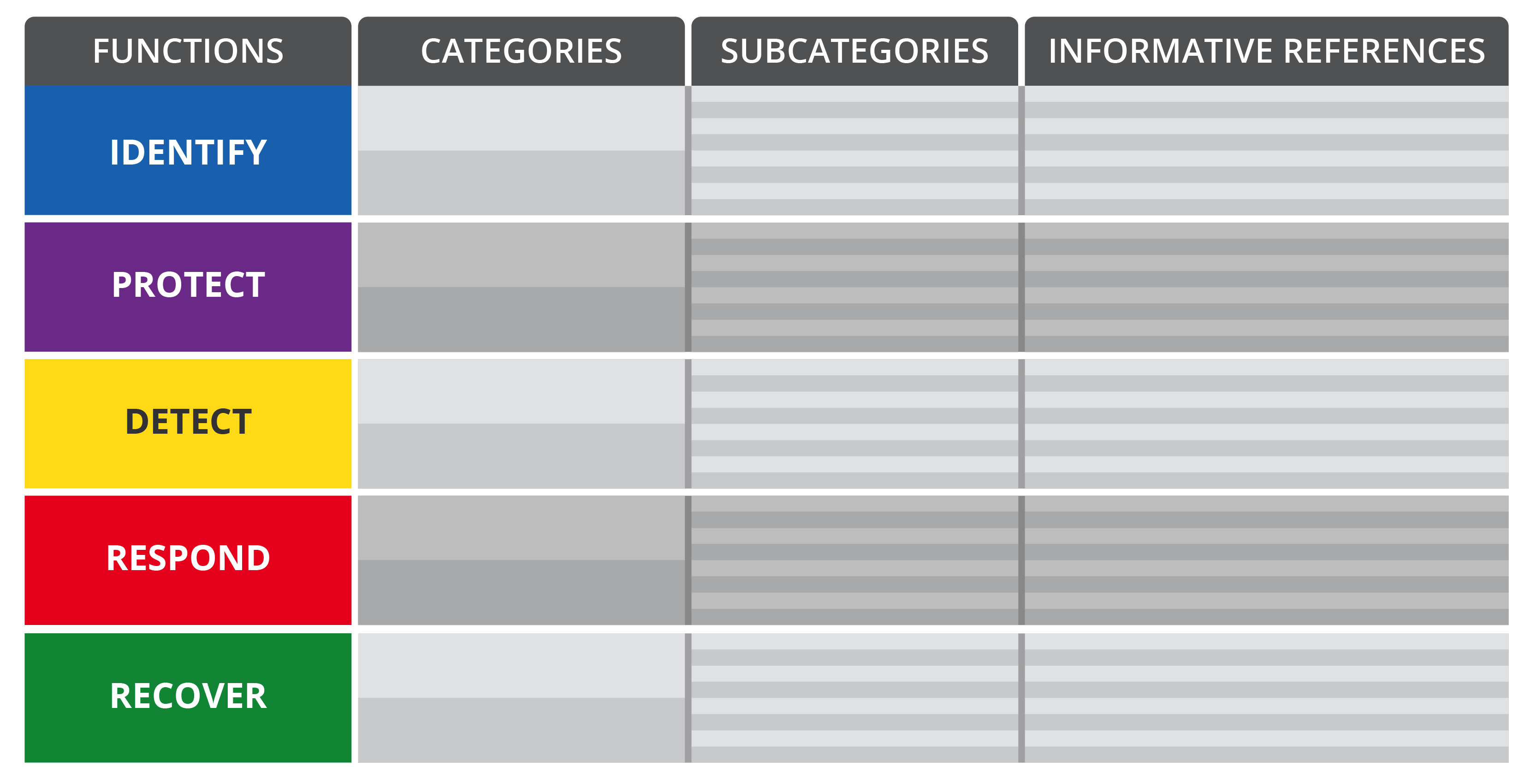
Categories subdivide Functions; Subcategories subdivide Categories; and Informative References map one-to-one to Subcategories to keep actions concrete and consistent.
Treat security as a continuous process. The threat landscape evolves; your program should too.
An Effective Response Program
A solid response program provides actionable activities when a security event occurs. If you prefer a formal mapping, NIST offers guidance across the Respond function:
| Publication(s) | Category |
|---|---|
| 800-34 Rev. 1 | Response Planning (RS.RP): Response processes and procedures are executed and maintained to ensure timely response to detected incidents. |
| 800-150 | Communications (RS.CO): Coordinate with internal and external stakeholders (including law enforcement) as appropriate. |
| 800-101 Rev. 1 | 800-72 | 800-168 | 800-86 | Analysis (RS.AN): Conduct analysis to support response and recovery. |
| 800-61 Rev. 2 | 800-83 Rev. 1 | Mitigation (RS.MI): Prevent expansion, mitigate effects, and resolve the incident. |
Use this as a starting point and adapt to your organization.
Responding to the Log4Shell Security Event
Log4Shell is a useful example because of its breadth and exposure via dependencies. When a pervasive event lands, assume compromise and work to disprove it. Two key questions:
- Are we affected by this?
- Have we been compromised?
Take a pragmatic approach to identification, prioritization, remediation, and communication.
1) Build Off What We Know
Log4Shell results from Log4j2’s interaction with JNDI in Java. Start by enumerating Java-based applications and their ecosystems. Think vendor advisories (e.g., hypervisors, management stacks) and first-party software. These are your “known knowns.”
2) Assess the Scope of Impact
Unknown unknowns are the challenge—Log4j may be embedded where you don’t expect. Use two complementary detection approaches:
| Technology | Category |
|---|---|
| Host-Based Detection | Tools that probe for the vulnerability and scan packages/JARs to locate affected libraries. |
| Network-Based Detection | Use logs and controls (WAF/IPS) to hunt for IOCs. JNDI payloads often leverage LDAP, DNS, RMI, etc. (e.g., ports 636, 53, 1099); pivot on unusual egress/ingress. |
If vulnerable, assume breach and work to disprove it with forensics and telemetry.
3) Prioritize Remediation
Not all instances have equal impact. Some are RCE, others may be info-disclosure. Use risk-based prioritization to sequence fixes (see MITRE’s guidance on risk impact assessment).
4) Remediate
With inventory and impact known, apply patches or compensating controls. For Log4Shell that included vendor advisories, disabling JNDI lookups, or removing vulnerable classes—see our deeper dive in Log4Shell – Lessons Learned. Also consider layered defenses (WAF/IPS) for future remotely exploitable issues.
5) Communicate
Define what/how/who communicates status. Expect updates to executives, internal stakeholders, and possibly customers. Close with a blameless review: what worked, what didn’t, what to automate, and what controls to add before the next event.
NOC — Authoritative DNS, CDN & WAF
Accelerate and protect your sites with global DNS, edge caching, and an always-on web application firewall.
See Plans