After a hack, should an organization restore its servers from a new OS or from the backup? This was the question in a recent incident response case. One camp said “always rebuild from fresh OS,” while another said “restore and patch.” Our answer: it depends. Below is a practical framework to decide—and to phase recovery to protect business continuity.
Balance Security Recommendations with Business Needs
Context matters. In this case nearly 100 servers were impacted by ransomware across core functions (HR, Finance, R&D, Operations, Marketing, Commerce). There was no dedicated security team, limited security knowledge, and little telemetry. The org didn’t know a) the entry vector or b) when intrusion began. In that scenario, you must assume worst case, which points to fresh OS builds—but can the business afford the downtime? Security exists to enable the business. Post-compromise, we must both eradicate the threat and ensure continuity. That drives a more nuanced, phased plan.
- Does the org have people to stand up a new environment?
- Is the needed expertise available?
- What are the config diffs between old and new?
- Which server types are we talking about?
- How long will it take (hours/days) with real confidence?
- Can the business tolerate that downtime?
Three Concepts That Set the Foundation
We recommend doing both (rebuild and restore)—but in phases—anchored on three concepts:
| Principle | Description |
|---|---|
| Categorization | Group systems into risk/impact buckets to sequence recovery. |
| Functional Isolation | One box, one job. Reduce blended roles that amplify blast radius. |
| System Boundaries | Define clear logical boundaries and traffic rules between tiers. |
With unknown root cause, you must plan for re-compromise upon power-up. The goal is to limit impact while restoring service, then drive toward fresh builds.
I — Categorize the Servers
Use a simple Low/Moderate/High impact model derived from the CIA triad:
Security Category (SC) =
{ (confidentiality, impact), (integrity, impact), (availability, impact) }
Example (personnel vs. admin data on a file server):
SC personnel = {(confidentiality, M), (integrity, M), (availability, L)}
SC admin = {(confidentiality, L), (integrity, L), (availability, L)}
SC file srv = {(confidentiality, M), (integrity, M), (availability, L)} → Moderate
II — Reduce Function Where Possible
Categorization exposes multi-purpose servers. Break roles apart where feasible to shrink attack surface and blast radius.
III — Establish New Boundaries
Group servers by category and enforce boundary rules (east-west controls, ACLs, firewalls, MFA). Review access and group design—who truly needs what?
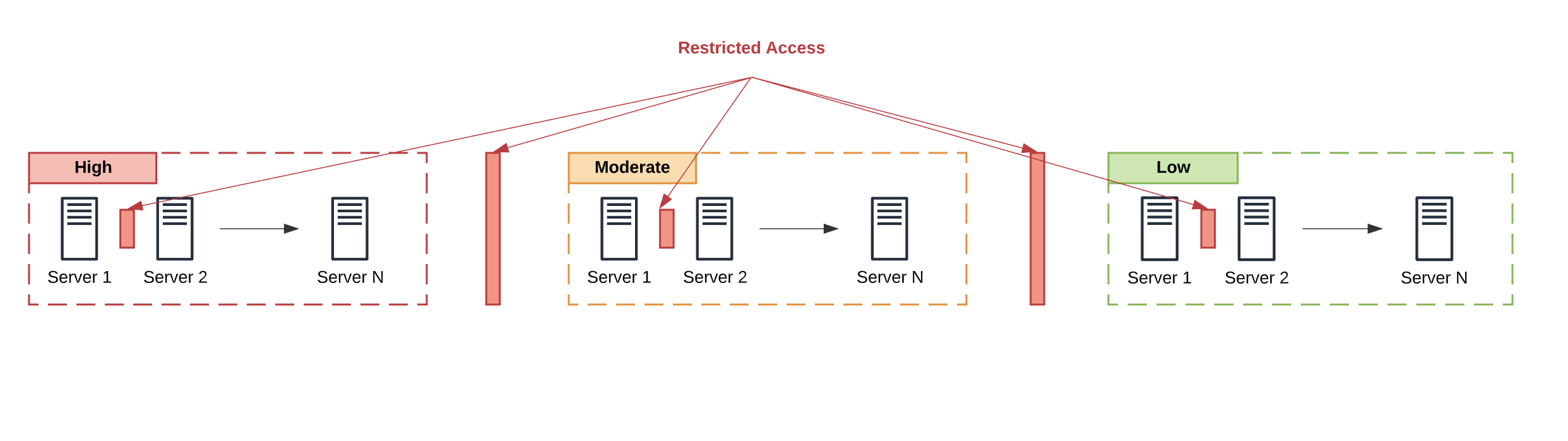
IV — Isolate Boundaries & Tighten Access
- Review and enforce access controls between/within boundaries.
- Refactor roles/groups; verify least-privilege and MFA on critical paths.
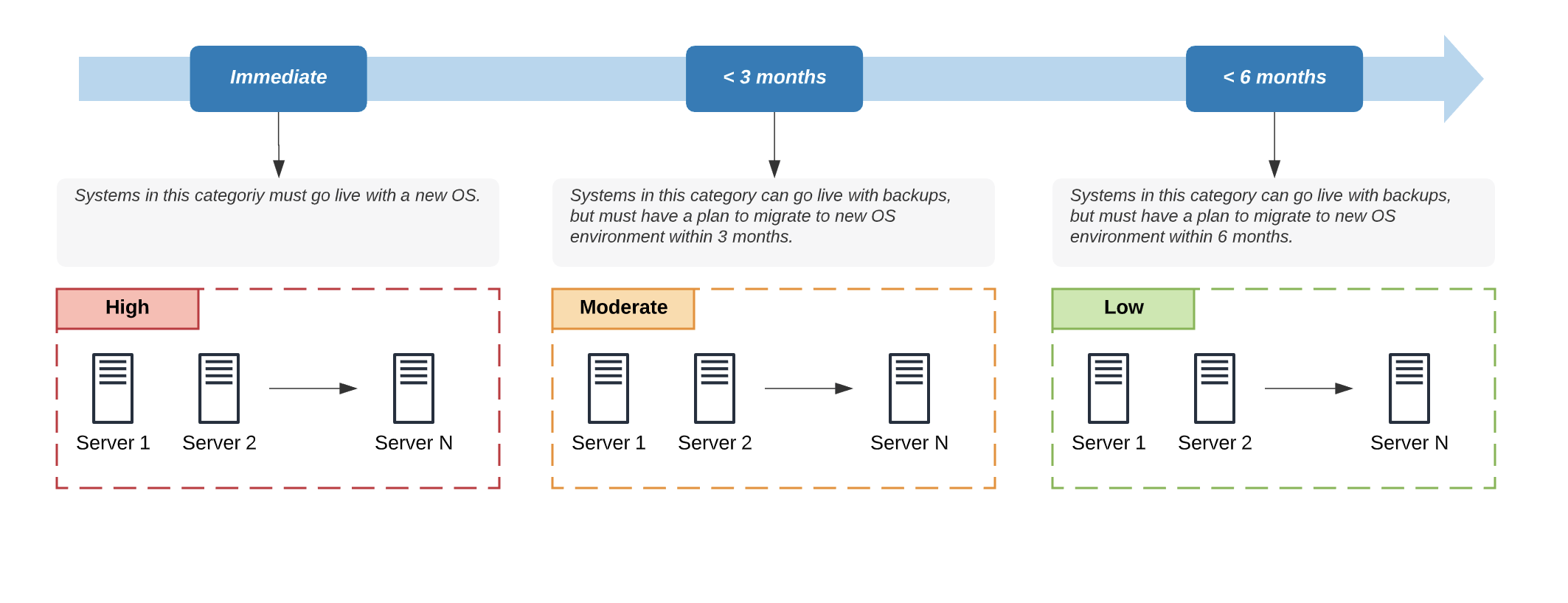
V — Phased Deployment
Sequence recovery by category. High-impact systems: fresh OS before going live. Lower-impact systems: restore with tight boundary controls, then plan rebuilds. This balances risk reduction with business continuity and moves you toward a clean steady state.
Working in a World of Unknowns
Security’s job is to help the business run. Be clear about ideal end-states but tailor the sequence to reality. When telemetry is thin and root cause unknown, make the best decisions you can, contain impact with boundaries, restore service safely, and drive to fresh builds on a sensible timeline.
NOC — Authoritative DNS, CDN & WAF
Accelerate and protect your sites with global DNS, edge caching, and an always-on web application firewall.
See Plans