If there is one thing that we have learned from vulnerabilities like Log4Shell, Heartbleed, Apache Struts Framework, Shellshock, and so many others is that when it comes to the components that power the web, the fabric of the internet, we are not prepared. That acknowledgement is critical in helping us psychologically acknowledge that security itself is not an absolute, it’s a continuously evolving domain and we must act, and prepare, accordingly.
This means that basic security governance and principles around Defense in Depth are critical to how we prepare our organizations for similar threats in the future. In this article we’ll focus specifically on one specific component of your security program – incident response and we’ll use the log4shell vulnerability as an example to build from.
A Basic CyberSecurity Framework
Before diving intot he example, we’ll take a moment to focus on some security framework fundamentals. We’ll leverage the US National Institute of Standards and Technology (NIST) CyberSecurity Framework to illustrate the importance of having a Response component as part of your overarching security program.
The NIST framework is built on 5 core elements: Functions, Categories, Subcategories, and Informative References. Their relationship is as follows:
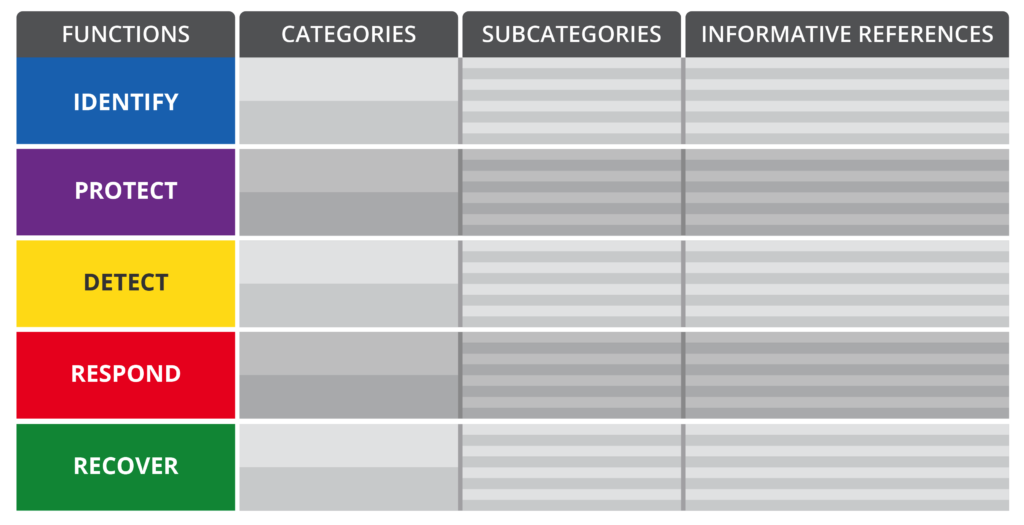
As the illustration shows, the categories are subdivisions of the functions, and the subcategories subdivisions of categories. There is a one to many relationship between Functions and Categories, and Categories and Subcategories. The informative references have a one to one relationship with the subcategories, they are important to ensure that everyone is aligned with the exact steps being leveraged for each control and action.
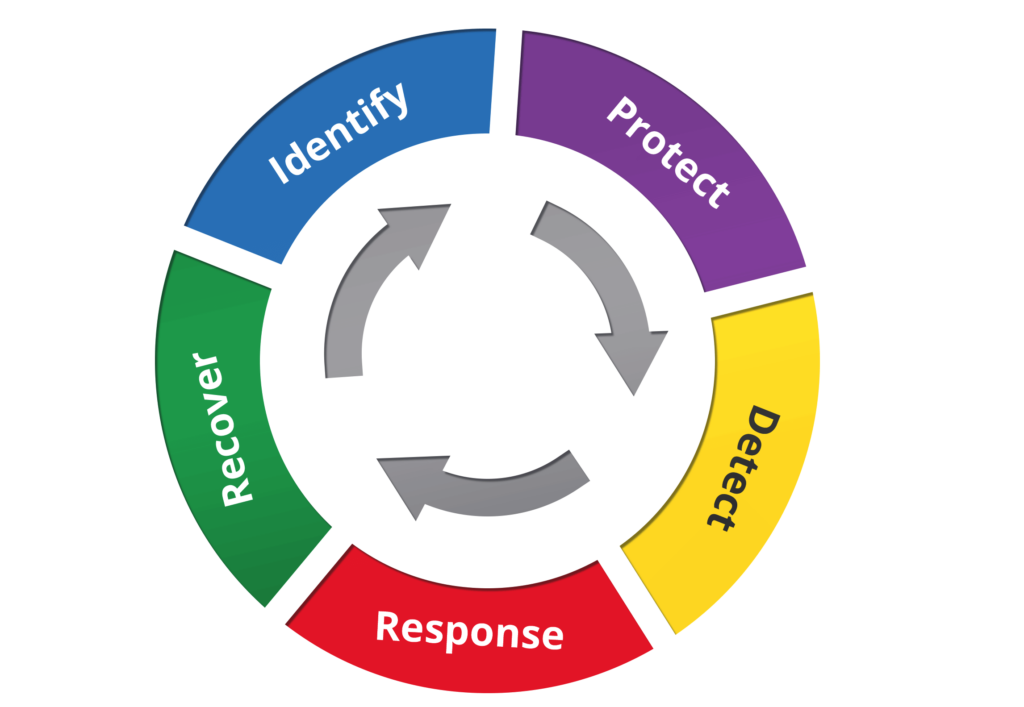
As you consider the framework, think of security as a continuous process. The threat landscape is constantly evolving, and as such, your security program should also evolve.
An Effective Response Program
Now that we’re on the same page in regards to what we’re referring to when we say a security program, let’s double-click into the “response” domain specifically.
An effective response program should consist of a series of activities that the team can take when a security event occurs. These activities help provide a rudder when things get choppy, and they always get choppy.
If you’re looking for a more formal framework for your response plan, below is what NIST provides as guidance for an appropriate response program:
| Publication[s] | Category |
|---|---|
| 800-34 Rev. 1 | Response Planning (RS.RP): Response processes and procedures are executed and maintained, to ensure timely response to detected cybersecurity incidents. |
| 800-150 | Communications (RS.CO): Response activities are coordinated with internal and external stakeholders, as appropriate, to include external support from law enforcement agencies. |
| 800-101 Rev. 1 | 800-72 | 800-168 | >800-86 | Analysis (RS.AN): Analysis is conducted to ensure adequate response and support recovery activities. |
| 800-61 Rev. 2 | >800-83 Rev. 1 | Mitigation (RS.MI): Activities are performed to prevent expansion of an event, mitigate its effects, and resolve the incident. |
We won’t dive into each one of these here, but if you’re trying to think about building a Response program, this is a great place to start.
Remember that, with anything in security, these are not written in stone – they are a compilation of recommendations that are designed to be adapted to your specific organization and needs.
Responding to the Log4JShell Security Event
Log4Shell is a great vulnerability to leverage as an example because of the breadth of its scope. As we discussed in our last article, log4shell is especially tricky because it highlights challenges we have in our software supply chains, specifically with “unknown unknowns” and dependencies.
When a security event this pervasive is identified, your response team should assume the mindset that a compromise has already occurred and it’s your job to disprove that. So when we approach an incident, there are two key questions we focus on:
- Are we effected by this ?
- Have we been compromised?
Note, it’s not about boiling the ocean in one shot. Instead, trying using a pragmatic approaching to identification, prioritization, remediation and communication.
1. Build Off What We Know
What do we know about Log4J?
It’s the relationship between the Log4J2 library and JNDI that make this a vulnerability. And we know that Log4J2 and JNDI are based on the Java platform. So this would tell us that the first thing to look for are Java based applications, and their corresponding ecosystems, in our networks.
For example:
Do you run VMWare in your environment? A lot of enterprises do, and so it’s especially important you’re aware of your vendors patches and updates. Now apply this same thinking to your other applications.
These would all be part of the “known knowns”. Things we should automatically assume are at risk, and potentially exposed.
What other Java based applications exist in your ecosystem that you’re aware of? Once you know what you have, you can work with the vendors to identify available patches and updates.
This is the easiest part.
2. Assess the Scope of the Impact
Now we have to turn our attention to the unknown unknowns.
Again, the big challenge Log4Shell presents is its breadth, the fact that it is likely integrated in areas we don’t even know exist. This means the biggest task is finding Log4J in your environment.
There are two very specific detection technologies you should consider:
| Technology | Category |
|---|---|
| Host-Based Detection | In our previous post we shared free and commercial options available to any organization. These solutions combine different technologies that test for the vulnerability, or analyze your local packages for the effected libraries. It works to identify instances of the exploitable vulnerability. |
| Network-Based Detection | Something we didn’t talk to is the power of having network solutions in place to help you not only detect, but mitigate this attack. For example, the JNDI feature allowed for the use of various different protocols like LDAP, DNS, RMI, etc.. These protocol all work off specific ports (e.g., LDAP [636], DNS [53], RMI [1099]) knowing this, we can use the logs in our environment to identify any communication that might be considered an Indicator of Compromise (IoC). |
Assessing the scope plays an integral part in helping you understand if you’ve been compromised. If you find that your environment was, is, vulnerable, it’s best to assume that you’ve already been compromised and work towards disproving that. This change in mindset is critical.
This is also a great time to leverage the other controls (i.e., logging, WAF’s, IPS, etc..) deployed in the environment to help gain a better picture of what is happening, and what has happened. In other words, once you identify you are vulnerable it should trigger a need for forensics to truly understand the full scope of the problem.
3. Prioritize the Remediation
In a world where everything is important, nothing is important. The same is true here. When working with issues like this you have to learn to prioritize those that things that have the potential to cause you the most grief.
For example, while Log4Shell is serious, not all instances of the vulnerability carry the same potential impact. While the vulnerability might exist, it doesn’t mean that it allows for a Remote Code Execution (RCE), there may be instances of information disclosure only. Understanding the impact is critical to maintaining your sanity and not getting lost in the noise.
This is known as risk prioritization, commonly found in vulnerability management programs. A program that is a critical piece of your overall incident response program. There are books written on this, along with almost everything else in this article, so I’ll point you to a great article by MITRE that talks to Risk Impact Assessment and Prioritization.
4. Remediate
The first three steps were about understanding the scope of the problem. Were you effected? Are you effected? Where do things exist? What is important? Now you can dive head first into the remediation phase.
Depending on the vulnerability, how a patch is updated can be simple or it can be tricky. Again, Log4Shell is a great example of one that is complicated.
Some of the more common enterprise applications have already pushed out advisories and patches (think VMWare), but many others might be in a very different boat and the patch might come down to your team to apply. In some instances, it might be as simple as applying flags to disable features, or modifying the classes directly. We dive deeper into these recommendations in our last article.
Once you know what you have, and its impact, the remediation step will become a lot clearer. Is there a patch available? Or will you need to perform manual intervention?
This is also a good time to start thinking about other defensive controls. Log4Shell is a great example of a remotely exploitable vulnerability. What technologies exist to help minimize the potential exposure for other similar vulnerabilities in the future? This might be where you look at Web Application Firewalls (WAF) or Intrusion Prevention Systems (IPS) to help bolster your organizations defenses.
5. Communicate
The last step, but not the least important, will be ensuring you have an appropriate communication plan in place.
If you’re on the security team you will be getting pressure from various functional groups, including the executive team. These will all be important stakeholders and as such, you will have an obligation to report on your findings. Depending on the type of application that is found to be effected, your company might also have a responsibility to provide a public disclosure to customers.
Either way, be sure to account for what, how and who will provide updates on the current state of affairs. This last step can often be overlooked, but after years of remediating compromised environments I can assure you that a poor communication plan can destroy all the hard work in an already stressful situation.
This communication phase should also serve as a medium to talk internally with your own team. An opportunity to share findings, identify learnings, and grow as a team. What are the things we could be doing to help reduce exposure in the future? Assume it’s going to happen again. Was our response fast enough? Did we know who to engage with? Did we have the right tools? What controls should we be thinking about? All things that should come up through this final phase.